Wat is linkwaarde en hoe kun je die sturen?

Hoe je vanuit zoekmachineoptimalisatie omgaat met dubbele content, gepagineerde content en content die niet (meer) beschikbaar is
Linkwaarde is de waarde die een url heeft voor zoekmachines. De linkwaarde van een website zegt iets over hoe belangrijk en relevant een zoekmachine de website vindt. Een link van een website met een hoge linkwaarde telt zwaarder dan een link van een website met een lage linkwaarde. Hoewel we spreken over link-‘waarde’, kan deze niet worden uitgedrukt in één cijfer. De waarde is dynamisch, situationeel en afhankelijk van context. In dit artikel ga ik uitgebreid in op wat linkwaarde is, hoe deze tot stand komt en hoe je deze kunt sturen.
Twee jaar geleden ben ik aan de slag gegaan met de zoekmachineoptimalisatie van Marketingfacts. In dit vierluik vertel ik, als niet-SEO’er, over mijn zoektocht en de kennis die ik daarin heb opgedaan. SEO door de ogen van een online marketeer, dus. Eerder publiceerde ik al ‘Klassieke SEO in een tijd van contentmarketing‘ over het optimaliseren van meta-informatie, en ‘Van informatie naar dingen: help Google te begrijpen wat er op je website staat‘ over het toepassen van schema.org-gegevensopmaak.
Hoe wordt de linkwaarde bepaald?
Aantal inkomende links
De linkwaarde (ook wel seo-waarde genoemd) hangt onder meer af van het aantal webpagina’s dat naar de pagina in kwestie linkt (ook wel inkomende links genoemd). In onderstaande voorbeeld heeft de eerste pagina de meeste inkomende links. Deze inkomende links kunnen zowel van andere websites afkomstig zijn als van pagina’s in het eigen domein. In onderstaande visualisatie heeft de eerste pagina 4 links van externe websites en 1 vanuit het eigen domein.
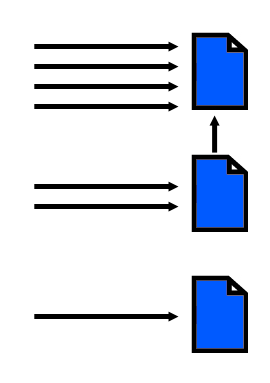
Variëteit van inkomende links
Hoe meer inkomende links, hoe beter dus. Dat is grotendeels waar, maar het is belangrijker dat de links van verschillende websites komen. Het is dus véél beter om van 100 websites 1 link te krijgen, dan 100 links van 1 website.
Kwaliteit van inkomende links
De kwaliteit van de inkomende links is de belangrijkste factor. Een link van een kwalitatieve of populaire website is meer waard dan een link van een website in de marge. Zo is een inkomende link van een pagina die op haart beurt weer veel inkomende links heeft meer waard dan een inkomende link van een pagina met weinig inkomende links.
Relevantie van inkomende links
Als we het hebben over relevantie, dan kijken we iets meer naar de context van een link. Als webpagina’s een bepaalde thematiek delen, is de link relevanter en daarmee de linkwaarde hoger. Zo is voor Marketingfacts een link van Frankwatching waardevoller dan een link van Geenstijl, ook al is de laatste groter.
Dat een website is z’n algemeen minder thematiek deelt met een andere website hoeft overigens niet te betekenen dat dat voor alle pagina’s op gaat. Zo is een inkomende link van de website van Burgers’ Zoo niet relevant voor Marketingfacts an sich, maar als het een link is naar dit artikel over Burgers’ Zoo, is het voor die pagina wel heel relevant. De thematiek wordt in toenemende pagina op paginaniveau beoordeeld en steeds minder op websiteniveau.
In het verleden publiceerde Google de linkwaarde wel publiekelijk, onder de noemer ‘PageRank’. De PageRank-score is sinds februari 2013 niet meer geactualiseerd en het voortbestaan (in de buitenwereld) lijkt op losse schroeven te staan – hoewel Google het intern nog wel gebruikt in het zoekalgoritme. Ook toolleveranciers, zoals Majestic, Moz en Link Research Tools, hebben eigen metrics bedacht om de linkwaarde in een cijfer uit te drukken.
Hoe stuur je linkwaarde?
Hierna ga ik in op de middelen die je tot je beschikking hebt om linkwaarde te sturen en verloren linkwaarde te voorkomen. Ik doe dit aan de hand van issues die ik tegenkwam bij het analyseren van Marketingfacts. Ook ga ik in op hoe je omgaat met dubbele content, verwijderde content en content die op een nieuwe locatie beschikbaar is.
Wat is er aan de hand?
Bij het inloggen in de Google Search Console (toen nog Google Webmaster Tools) zag ik twee jaar geleden dat het aantal geïndexeerde pagina’s enorm aan het groeien was. Dat is normaal goed nieuws, je wilt immers dat Google zoveel mogelijk content van je website indexeert. Echter, deze aantallen kon ik niet thuisbrengen, want zoveel pagina’s als gemeld, bijna 140.000, heeft Marketingfacts niet. Er leek dus iets vreemds aan de hand te zijn.
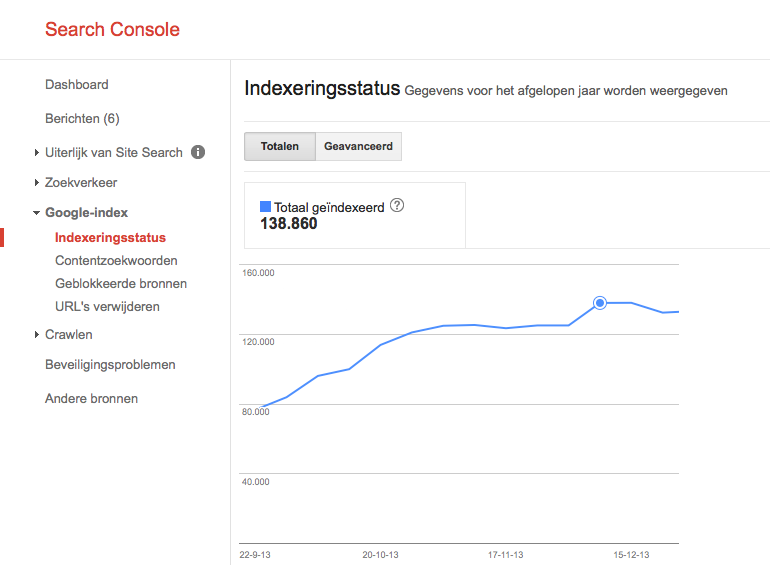
Dubbele content
Dubbele content, veelal duplicate content genoemd, is niets meer en niets minder dan de titel doet vermoeden: content die twee of meer keer voorkomt. Meestal als het over duplicate content gaat, hebben we het over dubbele pagina’s. Duplicate content ontstaat bijvoorbeeld wanneer een blogger zijn artikel zowel op Marketingfacts als op zijn eigen website publiceert. Of wanneer een website een artikel simpelweg kopieert, met of zonder toestemming. Voorop gesteld: zoekmachines houden niet van duplicate content. Het uitgangspunt daarbij is dat het geen waarde heeft voor de zoeker; die heeft er immers geen baat bij om meerdere zoekresultaten met dezelfde content gepresenteerd te krijgen.
Canonical-tag
Ook binnen je eigen website kan er duplicate content ontstaan. Dit gebeurt bijvoorbeeld wanneer je een desktop en mobiele versie hebt van je website die ieder op eigen url’s ‘draaien’. Of wanneer je een printversie van je pagina aanbiedt. Je wilt duplicate content zoveel mogelijk voorkomen. Daarvoor is een hulpmiddel in het leven geroepen: de canonical-tag. Dit stukje code zegt tegen zoekmachines welke url het origineel is en daarmee welke url geïndexeerd moet worden.
Een belangrijk voordeel van de canonical-tag is dat je beide pagina’s kunt behouden, maar de linkwaarde wel allemaal naar één pagina gaat, in plaats dat je hem verdeelt over meerdere pagina’s. Hoewel we voor Marketingfacts de gebruiker zoveel mogelijk naar één url sturen (een url zonder “www” wordt bijvoorbeeld automatisch doorgestuurd naar “www”), hebben we wel canonical-tags aangebracht voor als er toch onbedoeld alternatieve url’s zijn waarop een pagina te benaderen is.

In het geval van een mobiele versie, overigens, is het gebruikelijk om op de mobiele versie een canonical naar de desktopversie te plaatsen, in combinatie met een rel=”alternate”-tag (uitleg).
Onbedoelde dubbele content
Dat er onbedoeld meerdere url’s zijn waarop je content aanwezig is, is iets waar ik bij Marketingfacts zelf tegenaan ben gelopen. Bij het analyseren van het hoge aantal geïndexeerde pagina’s stuitte ik al snel op een groot aantal pagina’s met dezelfde titel.
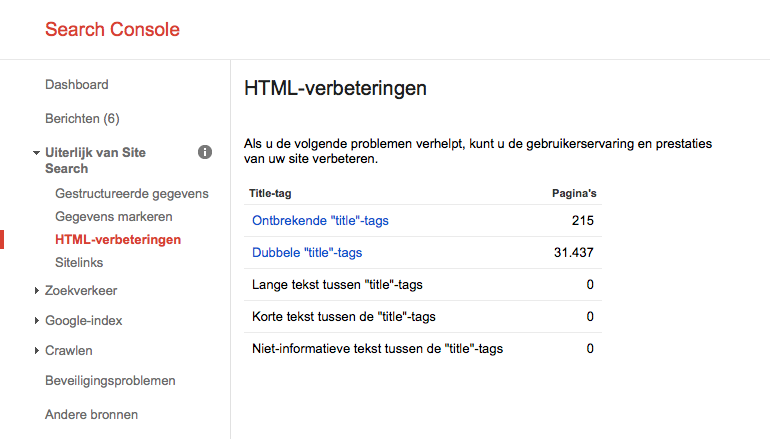
Toen ik dieper inzoomde op de url’s die dit betrof, kwam ik op een groot aantal url’s uit wat dezelfde titel had. Hierbij ging het vooral om artikelen, maar ook om rubriekenpagina’s. Wat bleek: als er aan het eind van de url karakters werden toegevoegd, bleef de url werken. Fijn voor de gebruiker, maar daardoor ontstaat er wel dubbele content.
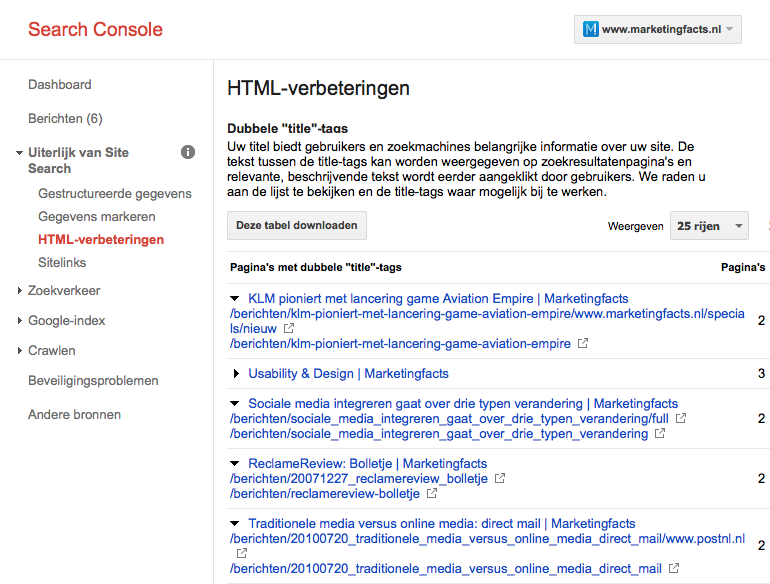
Een tweede issue zorgde ervoor dat dit probleem een vliegwiel werd: fout ingevoerde hyperlinks. Bijvoorbeeld hyperlinks waarbij “http://” ontbrak. Het gevolg daarvan is dat als een zoekmachine deze url volgt, hij bijvoorbeeld de url “[…]/20100720_traditionele_media_versus_online_media_direct_mail/www.postnl.nl” volgt. Omdat de zoekmachine op die url resultaat krijgt, indexeert hij die ook. Maar hier wordt het effect van het vliegwiel pas echt duidelijk: op deze pagina staat deze fout ingevoerde url natuurlijk ook. Dus als de zoekmachine deze pagina indexeert, volgt hij deze link weer, en volgt hij: “[…]media_versus_online_media_direct_mail/www.postnl.nl/www.postnl.nl”.
Crawl-budget
Belangrijk om te weten in dit kader is dat Google een maximumaantal pagina’s van je website indexeert. Dit wordt ook wel ‘crawl-budget’ genoemd. Remi van Beekum, cio van StormMC, legt uit:
Google heeft gigantische datacentra vol snelle servers om websites mee te crawlen en te indexeren. Maar ook de capaciteit van Google is beperkt. Daarom zal Google niet eindeloos doorgaan met het indexeren van een website. De hoeveelheid pagina’s die geïndexeerd zal worden, is bijvoorbeeld afhankelijk van de populariteit van je website als geheel en de mate waarin de content uniek is. Bij een website van een maand oud met vijf inkomende links zal Google geen 140.000 webpagina’s indexeren. Maar bij Marketingfacts, met tienduizenden inkomende links en dagelijks unieke nieuwe content, wel.
Webpagina’s waarvoor de zoekmachine langere wegen af moet leggen, vallen als eerste af. Het gevaar van duplicate content is dat de zoekmachine op deze foutieve pagina’s stuit voordat hij op de wat oudere, maar wel originele pagina komt. Duplicate content kan zo dus gewenste geïndexeerde content verdringen. Remi verduidelijkt:
Het archief van Marketingfacts gaat wel ruim 12,5 jaar diep, wat voor zoekmachines best een uitdaging is. We willen dus dat crawlers makkelijk en effectief bij alle relevante pagina’s komen en geen crawl-budget ‘verspillen’ aan onbelangrijke pagina’s, dubbele content, enzovoorts. Hou daarbij ook in het achterhoofd dat crawlers van veel andere zoekmachines minder diep gaan.
Neem onderstaande fictieve situatie, waarbij Google maximaal 13 webpagina’s indexeert. Omdat Google eerder op enkele foute webpagina’s stuit, worden twee juiste webpagina’s niet geïndexeerd.
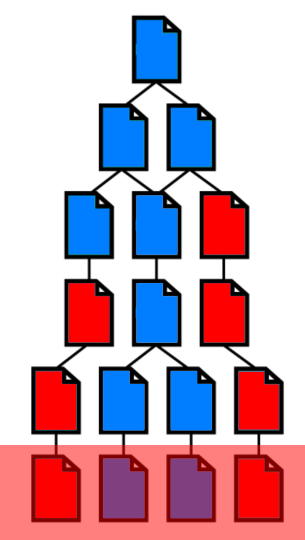
De oplossing
Het probleem en het effect is duidelijk. Tijd om het probleem te verhelpen. Daarvoor was het allereerst zaak om de fout ingevoerde url’s te verhelpen. Zo worden hyperlinks in het profiel van de auteurs (bijvoorbeeld links naar hun Facebookprofiel of eigen website) nu automatisch voorgegaan door “http://” als de auteur dit is vergeten. Bovendien heb ik een query geschreven die eenmalig alle reeds ingevoerde foute hyperlinks fixte en zijn foute hyperlinks in artikelen aangepast.

Tweede deel van de oplossing is om bezoek aan de foute url’s door te sturen naar de nieuwe url’s. Dit gebeurt met een 301-redirect. Met een 301-redirect vertel je zoekmachines dat de content op de bewuste pagina permanent te vinden is op een nieuwe url. De linkwaarde wordt daarom doorgegeven aan de nieuwe url.
Zo wordt voor Marketingfacts met een 301 redirect bezoek aan “[…]/20100720_traditionele_media_versus_online_media_direct_mail/www.postnl.nl/www.postnl.nl” nu automatisch ‘doorgestuurd’ naar “[…]/20100720_traditionele_media_versus_online_media_direct_mail” en wordt de linkwaarde meegegeven.
Voorkomen is beter dan genezen!
301’s en canonicals zijn geschikte manieren om de schade van het probleem te verhelpen en dubbele content voorkomen. In essentie geef je met een hyperlink aan dat Google de doelpagina kan indexeren. Pas bij het ophalen ziet Google de eventuele 301 of canonical. Google is dan echter al wel een stap verder en dat kost crawl-budget dat hij ook had kunnen inzetten om iets nuttigs van de site te indexeren.
Door onjuiste links te repareren, pak je de oorzaak aan en voorkom je dat foute links je crawl-budget kosten.
www en trailing slash
Trailing slash? Hiermee wordt bedoeld de “/” aan het einde van een url. Soms worden url’s wel gevolgd door een trailing slash, soms ook niet. Het gevolg hiervan is dat er twee url’s zijn met dezelfde content. Zoekmachines zien zodoende “marketingfacts.nl/rubrieken/zoekmachine_marketing” (zonder “/” op het eind) en “marketingfacts.nl/rubrieken/zoekmachine_marketing/” (mét “/” op het eind) als twee aparte pagina’s. Het is onwenselijk om content maar op één van deze twee locaties beschikbaar te maken. Daarom kun je het beste:
- óf met een canonical-tag het origineel aangeven,
- óf bezoekers van de ene url doorsturen naar de ander. Voor Marketingfacts heb ik voor het laatste gekozen en wordt bezoek aan “[…]/20100720_traditionele_media_versus_online_media_direct_mail/” automatisch met een 301-redirect doorgestuurd naar “[…]/20100720_traditionele_media_versus_online_media_direct_mail“.
Voor “www” geldt hetzelfde. Bij veel hostingbedrijven is je content automatisch mét www en zonder www beschikbaar. Ook dan is je content op twee locaties beschikbaar en is het verstandig om voor een van bovenstaande oplossingen te kiezen. Voor Marketingfacts heb ik ervoor gekozen om non-www door te sturen naar www met een 301-redirect.
Tip: je kunt voor de zekerheid ook “ww.” en “wwww.” aanpakken. Daarmee vang je een tweetal veelvoorkomende typo’s af.
Juiste interpretatie van url-parameters
URL-parameters zijn variabelen die aan het eind van url’s kunnen worden toegevoegd om aan te passen of om simpelweg informatie door te geven. Voorbeelden van url-parameters zijn “utm_source”, “utm_medium”, “utm_campaign”, “utm_content” en “utm_term”, waarmee je kunt doorgeven via welke website, pagina, element of tool een bezoeker komt. Deze paramaters geven alleen informatie door, de content van de website blijft onveranderd. Daardoor heb je 2 of meerdere url’s die allemaal dezelfde content hebben. Nou kent Google de utm-tags en snapt daarom dat het de website niet aanpast. Het zal daarom alleen de ‘representatieve url’ indexeren.
Van andere url-parameters weet Google dit niet. In Search Console kun je onder ‘crawlen -> url-parameters’ vertellen hoe Google moet omgaan met url-parameters.
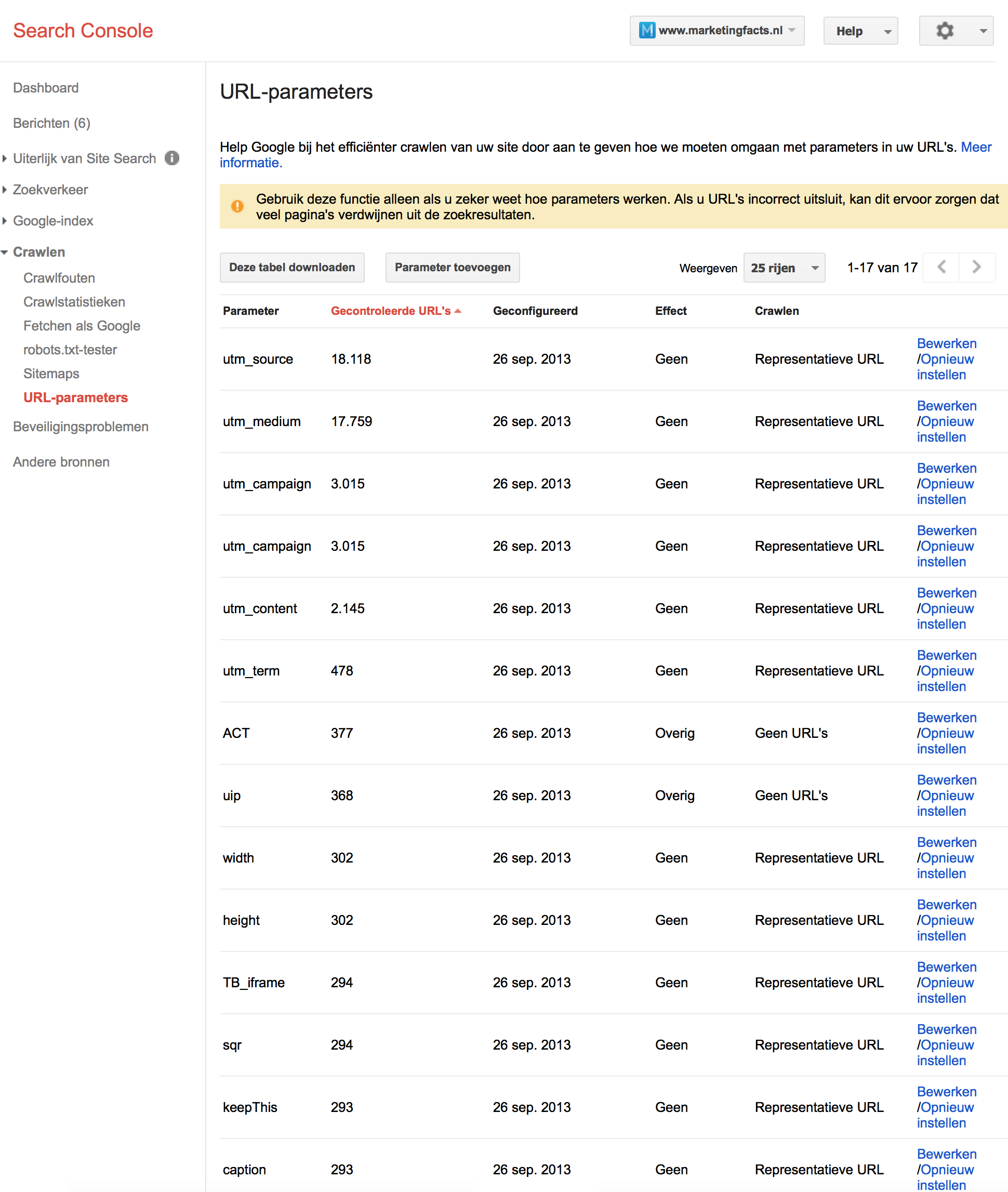
Goed om nog even te vermelden is dat deze oplossing ‘Google-only‘ is. Je pakt een probleem hier niet bij de bron aan, maar maakt een fix voor Google. Andere zoekmachines zullen daardoor wellicht nog steeds met het zelfde probleem zitten. Het is dus veel effectiever om het probleem bij de oorzaak aan te pakken!
Cookiemuur
Een bijzondere vermelding in dit kader is de cookiemuur. Vanwege de cookiewet tuigen veel websites op dit moment een cookiemuur op. Zo ook Marketingfacts. Middels een cookiewall dienen bezoekers bij hun eerste bezoek het plaatsen van cookies toe te staan om toegang te krijgen tot de webpagina. Vanuit seo-perspectief is dit echter onwenselijk. Je wilt immers niet dat zoekmachines en sociale media een cookiemuur te zien krijgen en die gaan indexeren.
Om dit te voorkomen, hebben we samen met ons webbureau Mangrove een aantal zaken toegepast om dit voor Marketingfacts te voorkomen. Allereerst wordt middels geo-filtering en whitelists (op basis van IP of de user agent string) zo goed mogelijk voorkomen dat bots, spiders en crawlers worden doorgestuurd naar de cookiemuur.
Om diensten die Marketingfacts willen indexeren en toch op de cookiepoort stuiten zo goed mogelijk hun werk te laten doen, is er nog een aantal maatregelen genomen:
- De doorverwijzing naar de cookiepoort verloopt via een 302-redirect – een tijdelijke doorverwijzing. Wanneer de doelpagina al is geïndexeerd, weet de dienst in kwestie dat hij deze niet moet overschrijven met informatie van de cookiepoort.
- Mocht de 302-redirect niet worden opgepakt, dan heeft de cookiepoort een canonical-tag met daarin de url van de pagina die de bezoeker opvroeg. Daarmee weet de dienst dat de originele content op die url terug te vinden en dat het niet de meta-informatie van de cookiepoort moet indexeren.
Content die niet (meer) beschikbaar is
Nou kan het gebeuren dat er content is die niet meer beschikbaar is óf die nog wel beschikbaar is, maar niet op dezelfde locatie. Ook dit was op Marketingfacts het geval. Dit kwam voor door:
- Advertorials en vacatures staan gedurende een beperkte periode live. Na deze periode is deze content niet meer beschikbaar.
- Legacy. Op het moment dat ik met de seo-activiteiten aan de slag ging, bestond Marketingfacts 10 jaar. In die periode zijn er meerdere redesigns geweest en zijn er onderdelen gestart en gestopt.
Content die niet meer beschikbaar is
Door het ontbreken van een 404/link-beleid kregen bezoekers van content die niet meer beschikbaar is wél het ontwerp van de website te zien, maar géén content. Een ongewenste situatie dus, zowel voor de bezoeker als voor de zoekmachine. We willen immers niet dat zoekmachines lege pagina’s indexeren. Hoewel er wel een 404-pagina was, werd deze niet overal waar het moet aangeroepen. 404 is een van de standaard-statuscodes die aangeeft dat een webpagina niet (meer) bestaat. Google kent twee soorten 404’s:
- Harde 404: de bezoeker krijgt een 404-pagina te zien waarbij wordt verteld dat de content niet (meer) bestaat. Je kunt de bezoeker op een 404-pagina suggesties doen waar hij de content mogelijk wel kan vinden. Ook geeft de pagina een statuscode mee, zodat zoekmachines weten dat de content op deze pagina niet (meer) beschikbaar is.
- Zachte 404: een zachte 404 treedt op als je geen 404-pagina toont en er ook geen 404-statuscode wordt meegegeven aan Google, maar Google wel zelf ziet dat de content niet (meer) bestaat.
Het startpunt om te ontdekken welke content niet (meer) beschikbaar is, is Search Console’s ‘crawlfouten’. URL’s waarbij er wel een 404-pagina wordt getoond vind je onder ‘niet gevonden’, url’s waarbij een 404-pagina ontbreekt vind je onder ‘softe 404’.
Met de tool Screaming Frog SEO Spider kun je zelf je website crawlen om na te gaan welke hyperlinks op je website dode links zijn. Het voordeel van een dergelijke tool is dat je, na aanpassingen te hebben doorgevoerd, niet hoeft te wachten totdat de Google-spider je website bezoekt. Bovendien beschik je over een zeer uitgebreid rapport van alle pagina’s, in plaats van alleen de top-1.000 fouten.
Voor verlopen advertorials en vacatures was het dus zaak om een 404-pagina te tonen, omdat deze content niet meer beschikbaar was. In het overzicht van ‘softe 404’s’ kwam ik ook website-onderdelen tegen waarvan ik zelf nog nooit gehoord had, maar die in het verleden wel bestonden. Neem contentpagina’s over het Marketingfacts Magazine waar ooit plannen voor waren, of over de Marcom100. Ook deze url’s hebben een 404 gekregen.
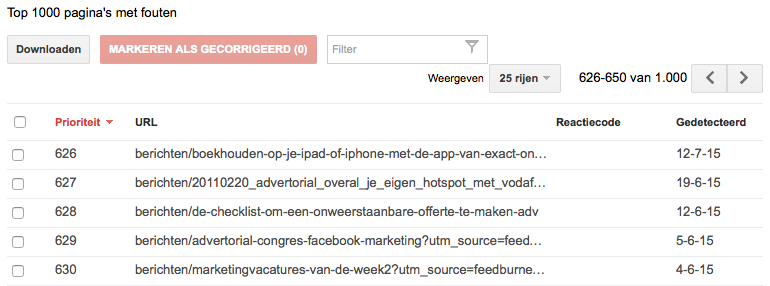
Standaard toont Search Console de ’top-1.000 pagina’s met fouten’. Deze lijst met fouten is niet altijd actueel, je moet soms lang wachten totdat Googje al je bijgewerkte webpagina’s heeft bezocht. Mocht je tegen deze issues aanlopen, zoals ik deed voor Marketingfacts omdat ik tegen veel meer dan 1.000 pagina’s met fouten aanliep, dan kun je ook tools als Xenu Link Sleuth (Windows) of Integrity (Mac) gebruiken. Met deze tools kun je zelf je website crawlen en zien waar er fouten ontstaan.
Content die op een andere locatie beschikbaar is
Bij het doorbladeren van crawlfouten in Search Console stuitte ik op categorieën die in het verleden wel beschikbaar waren, maar in de loop der tijd zijn verwijderd. Een greep uit deze categorieën zijn ‘domeinnamen’, ‘events’ , ‘klantrelatie’, ‘narrowcasting’, ‘viral marketing’, ’rss marketing’ en ‘bier, seks en reclame’. Deze categorieën huisvestten artikelen die nog altijd beschikbaar zijn. De categorieën zijn in de loop der tijd waarschijnlijk verwijderd omdat de onderwerpen hun actualiteit verloren. Deze wilde ik om meerdere redenen herstellen:
- Context: onderwerpen of tags geven context aan artikelen.
- Linkwaarde: het herstellen van linkwaarde die verloren is gegaan.
- Relevant alternatief: de bezoeker een relevant alternatief bieden voor content die nog beschikbaar is.
Herstellen van linkwaarde die verloren is gegaan
Hier ga ik wat dieper in op wat er gebeurt als je een pagina verwijdert. Als je een link beschouwt als het doorgeven van linkwaarde naar andere pagina’s, dan betekent het verwijderen van een pagina dat linkwaarde die die pagina heeft opgebouwd niet meer wordt doorgegeven aan andere pagina’s. En dat is zonde, zeker als er pagina’s zijn met een hoge linkwaarde.
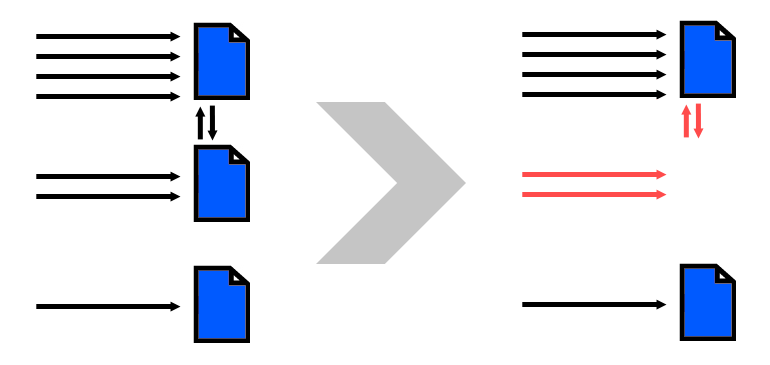
In Search Console kan je op een foute url klikken en zien vanaf welke plekken er naar die pagina gelinkt wordt. Voor pagina’s met veel externe links (en daardoor waarschijnlijk een hoge linkwaarde) is het interessant om te kijken of je relevante content hebt waar je deze heen kunt leiden.

Als je bezoekers wilt herleiden naar een andere pagina en daarbij de linkwaarde wil doorgeven, dien je een 301-redirect in te stellen. Met een 301 vertel je zoekmachines dat de content op de bewuste pagina permanent te vinden is op een andere url. De linkwaarde wordt daarom doorgegeven aan de nieuwe url.
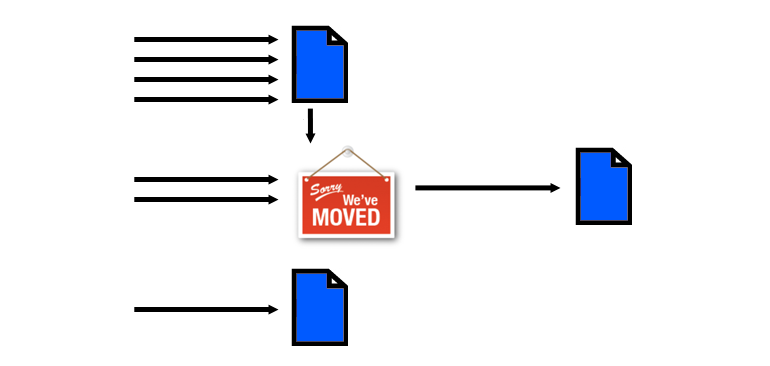
Voor Marketingfacts heb ik sommige categorieën met een 301-redirect verwezen naar andere plekken waar vergelijkbare content werd ontsloten. Zo is de oude rubrieken ‘cijfers & feiten’ gereroute naar ‘onderzoek’, ‘social networks’ naar ‘social media marketing’ en ‘weblog en rss’ naar ‘bloggen’. Daarnaast heb ik andere oude rubrieken in ere hersteld. Zo is er nu weer een topic ‘bier, seks en reclame’, ‘rss marketing’ en ‘narrowcasting’.
Gepagineerde content
Op Marketingfacts publiceren we op dit moment dagelijks gemiddeld 4 tot 5 artikelen. Dit zijn wekelijks, maandelijks, jaarlijks behoorlijk wat verhalen. Zou je deze allemaal op de homepage laten zien, dan zou deze pagina enorm lang worden en daarmee niet prettig voor de gebruikservaring. Bovendien duurt het laden van de webpagina dan erg lang.
Dat is waarom websites content pagineren. Andere situaties wanneer websites content pagineren:
- Nieuwssites die een lang artikel over verschillende kortere pagina’s verdelen; dit gebeurt vaak voor het genereren van meer page- en daarmee advertentieviews.
- Discussieforums verdelen threads vaak over opeenvolgende url’s.
Het pagineren van content mag dan commercieel of qua gebruikservaring voordelen opleveren, voor de linkwaarde is het nadelig. De linkwaarde van het artikel wordt immers over meerdere url’s verdeeld. Om dat te voorkomen, zijn de rel=”next”- en rel=”prev”‘-tags geïntroduceerd. Je kunt de rel=”next”- en rel=”prev”-tags gebruiken om de relatie tussen url’s aan te geven. Je gebruikt rel=”next” en rel=”prev” in combinatie met rel=”canonical”. “http://www.example.com/article?story=abc&page=2&sessionid=123″ kan bijvoorbeeld de volgende tags bevatten:
<link rel=”canonical” href=”http://www.example.com/article?story=abc&page=2″/>
<link rel=”prev” href=”http://www.example.com/article?story=abc&page=1&sessionid=123″ />
<link rel=”next” href=”http://www.example.com/article?story=abc&page=3&sessionid=123″ />
Dankzij deze markering behandelt Google deze pagina’s als een logische reeks en wordt alle linkwaarde bij elkaar opgeteld. Stel dat er 50 links verwijzen naar /P10, 40 naar /P20 en 30 naar /P50, dan wordt alle linkwaarde bij elkaar opgeteld en toegekend aan één url: de beginpagina. In mijn laatste artikel in deze reeks over seo zal ik nog dieper ingaan op het gebruik van de rel=”next”- en rel=”prev”-tags.
Content uitsluiten
Sommige webpagina’s of content wil je niet door zoekmachines laten indexeren. Neem webpagina’s die alleen voor intern gebruik bedoeld zijn, sitemaps of mappen met downloads. Dit zijn issues waar ik voor Marketingfacts tegenaan liep. Dergelijke fouten kun je oplossen met robots.txt. Het robots.txt-bestand is een instructiebestand voor zoekmachines. Deze wordt vooral gebruikt om zoekmachines te vertellen welke content moet worden uitgesloten van indexatie. Het bestand wordt altijd in de hoofdmap van een website geplaatst. In Search Console kun je onder ‘crawlen -> robots.txt-tester’ zien hoe Google je robots.txt-bestand inleest.
Naast robots.txt kan je ook content uitsluiten van indexatie middels de meta-tag ‘robots’. Hiermee kan je aangeven of robots (zoals Google) de webpagina mogen indexeren en of ze de links in het artikel mogen volgen. Het verschil met robots.txt is dat in het geval van de robots meta-tag de spider van Google wel eerst op de pagina komt, bij robots.txt niet. Zodoende blokkeert robot.txt het crawlen van Google door je website, daar waar ‘noindex’ alleen het indexeren voorkomt. Dit heeft dus ook effect op je crawl-budget. Zeker bij het structuren met grote aantallen van dit soort pagina’s kan dat een issue zijn. Als Google grote aantallen pagina’s moet crawlen om te ontdekken dat de pagina’s niet geïndexeerd mogen worden, is dat zonde.
Een detail is dat je middels robots.txt niet helemaal kunt voorkomen dat Google je webpagina(‘s) indexeert. Bij het gebruik van robots.txt om webpagina’s te blokkeren, stopt de crawler wanneer hij bij deze webpagina aankomt. Vanwege inkomende links van andere websites komt de crawler echter wel op deze webpagina terecht en zodoende weet de zoekmachine van het bestaan van de url af. De weergave van deze url op de zoekresultatenpagina wordt vervolgens samengesteld op basis van bijvoorbeeld de linktekst. Wil je zeker weten dat je webpagina niet in Google te vinden is, gebruik dan de meta-tag ‘robots’ met de waarde ‘noindex’. Zorg er dan wel voor dat de webpagina niet is uitgesloten in robots.txt, want dan kunnen zoekmachines de meta-tags op de webpagina niet ophalen. Meer over de meta-tag ‘robots’ lees je in het vierde artikel.
Overig: het no-follow-attribuut
Zoekmachines gaan er standaard vanuit dat de links die ze volgen organisch totstandkomen. Voor het gros van de content op Marketingfacts gaat dit ook op. Een uitzondering daarop zijn advertorials. Advertorials zijn immers betaalde plaatsingen, en de links naar externe sites komen zodoende niet op een natuurlijke wijze tot stand. Daarom dien je, volgens de richtlijnen van Google, de zoekmachine te vertellen dat het deze link niet moet volgen. Dat kun je doen door het ‘nofollow’-attribuut toe te voegen aan een hyperlink. Hiermee wordt de link wel gevolgd, maar weet Google dat het een betaalde link is en zal het geen linkwaarde doorgeven. Je kunt ook een nofollow toevoegen als je om een andere reden geen linkwaarde wilt doorgeven. Zie een link als een aanbeveling. Als jij een link plaatst naar een casinowebsite, dan wordt je daarmee geassocieerd. Nofollow houdt dat tegen.
Het effect
Reductie van foute webpagina’s
Er was zonder twijfel een aantal ernstige issues die de seo van Marketingfacts schaadden. De constateringen die ik in dit artikel heb beschreven, en de reparaties die daaruit voortvloeiden, vonden plaats van eind 2013 tot ongeveer maart 2014. Daar waar ik in eerste instantie fouten dacht op te lossen, nam het aantal fouten juist toe. De reden hiervoor is dat er nauwelijks een 404-beleid was. Hierdoor kregen bezoekers van content die niet meer beschikbaar is wél het ontwerp van de website te zien, maar géén content (zie paragraaf ‘Content die niet meer beschikbaar is’). Dit kwam ook door het eerder omschreven vliegwiel dat nog actief was: elke keer als er fouten werden weggetikt, werd de plek ingenomen door nieuwe foute pagina’s.
Daarbij is het ook goed om te noemen dat de foutenopsporing een iteratief proces is. Dat wil zeggen dat zodra je in Search Console duikt, de ernstige fouten het meest opvallen. Naarmate je fouten repareert, komen er weer nieuwe issues aan het licht. Zo duurde het ook bij mij even voordat ik alle fouten in de smiezen had. Zodoende zie je in onderstaande grafiek ook dat er een flinke tijd over heen ging voordat het aantal fouten afnam.
Bovendien duurt het altijd even voordat je het resultaat van aanpassingen zichtbaar zijn in Google en in Google Search Console. Google moet je website immers crawlen en met name voor de webpagina’s die zich dieper in je sitestructuur begeven, kan het even duren voordat ze bezocht worden. Ook dit werd verergerd door het vliegwiel van fouten. Inmiddels was de vertakking van foute url’s zo diep (denk aan het niveau “http://www.marketingfacts.nl/20100720_traditionele_media_versus_online_media_direct_mail/
www.postnl.nl/nl.wikipedia.org/www.postnl.nl/www.postnl.nl/www.postnl.nl/nl.wikipedia.org/
www.postnl.nl/www.postnl.nl”) dat het erg lang duurde voordat Google overal bij kwam. Na alle aanpassingen zag ik pas eind mei dat het aantal fouten afnam.

Een jaar later, op begin augustus 2015, staat het aantal webpagina’s dat niet gevonden kan worden op 4.900. Hoewel dit hoog klinkt, is het voor Markeitngfacts een acceptabel aantal. De fouten die zijn overgebleven bestaan uit advertorials, vacatures en andere content die in het verleden online heeft gestaan, maar nu niet meer beschikbaar is. Er staat bovendien fouten tussen waar we niks aan kunnen doen. Deze worden veroorzaakt door onjuiste hyperlinks van andere websites. Waar je deze op je eigen website kunt repareren, heb je geen controle over hyperlinks van andere websites.
Aantal geïndexeerde webpagina’s
De aanpassingen hebben ervoor gezorgd dat het aantal geïndexeerde webpagina’s is gedaald tot ruim 40.000. Een flinke daling ten opzichte van eind 2013, toen er op het hoogste niveau bijna 140.000 webpagina’s door Google waren geïndexeerd. Zoals ik eerder in het artikel schetste, bestond dat voor een groot gedeelte uit foute webpagina’s.
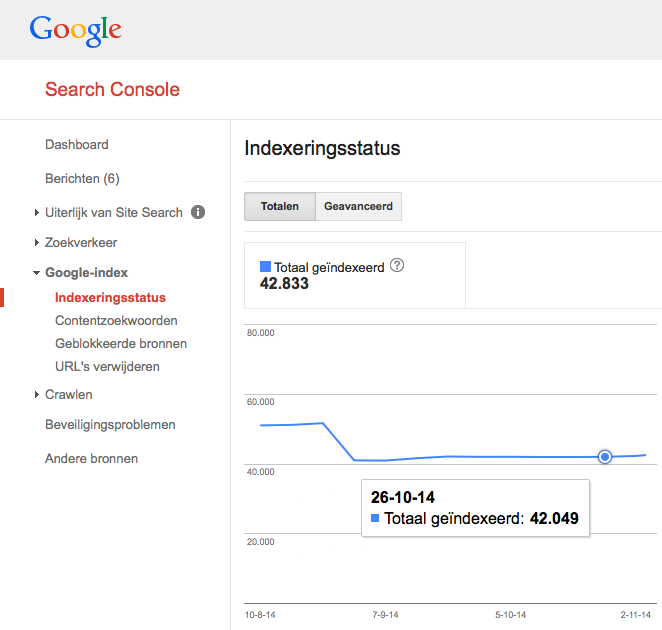
De huidige indexeringsstatus is realistisch en, belangrijker nog, bevat (vrijwel) alle content die Marketingfacts biedt: bijna 25.000 artikelen en de rest wordt opgemaakt door rubriekenpagina’s, topicpagina’s, typepagina’s, de vacaturebank, stagebank, profielpagina’s, de kennisbank, het statistieken-dashboard en informatiepagina’s (Marketingfacts Jaarboek, Colofon, etc). Dit is ook terug te zien onder ‘crawlen -> sitemaps’ in Search Console. Zoals je in het overzicht kunt zien, zijn vrijwel alle url’s geïndexeerd die de sitemaps naar Google verzenden.
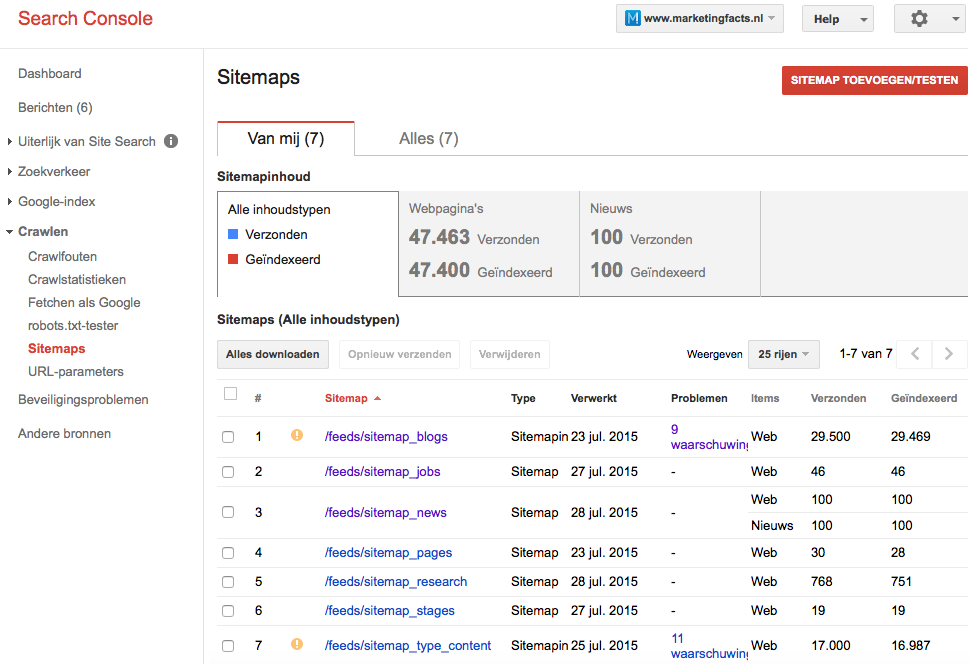
Mocht je denken: “Hé, dat zijn veel meer dan 25.000 artikelen”, dat klopt. Omdat artikelen meerdere rubrieken en tags kunnen hebben, bevinden deze artikelen zich in meerdere sitemaps. Search Console toont het aantal verzonden url’s, niet het aantal unieke url’s.
Afsluitend
In dit artikel heb ik geprobeerd uit te leggen wat linkwaarde is en hoe het zich gedraagt. Bovendien heb ik aan de hand van de case van Marketingfacts laten zien hoe je fouten vindt en vervolgens kunt oplossen om zo foute webpagina’s in Google te voorkomen, die mogelijk juiste webpagina’s verdringen.
Bovendien heb ik laten zien hoe je verloren linkwaarde kunt herstellen, zoals ik voor Marketingfacts heb gedaan voor in het verleden verwijderde rubrieken.
De fixes die ik heb gedaan, hebben ertoe geleid dat het aantal fouten en het aantal geïndexeerde webpagina’s drastisch is gedaald. Maar belangrijker is dat de webpagina’s die geïndexeerd moeten worden, nu geïndexeerd worden. Een schone, complete index dus.
Ik wil Eduard Blacquière, Remi van Beekum, Martijn Hoving en Jordy Noll bedanken voor het sparren en de zeer waardevolle feedback op dit artikel. In het volgende artikel en laatste artikel ga ik in op sitestructuur.

Data-gedreven digital marketeer. Resident bij Amdax en Woonduurzaam. Daarnaast vertel ik vaak als spreker over data-gedreven marketing. Auteur van het boek Data-bedreven marketing. Eén van de twee Groene Nerds.
Danny,
Oude content kan ook 301 redirects opleveren binnen je website. Dus er is een artikel op marketingfacts die linkt naar een pagina maar die wordt verplaatst of verwijdert. Vervolgens heb je een 301 redirect binnen je website.
In het geval van marketingfacts is dit ongeveer 10% van het totaal aantal te linken pagina’s.
Dit is mbt linkwaarde niet een wenselijke situatie. Bij een 301 redirect verlies je linkwaarde (ongeveer 15%). Vanuit andere websites kan je er niets aan doen, echter binnen je website kan het wel. Immers, je kan zelf de ingaande link wijzigen.
@Danny: wederom complimenten voor het uitgebreide artikel!
Wellicht nog een handige toevoeging aan het omgaan met oude content die ik weinig toegepast zie: de 410 Gone header. Vanuit crawlbudget gezien een betere en meer efficiente oplossing om oude pagina’s uit de index te halen van Google. 3xx en 404 status pagina’s zullen altijd nog een aantal keer gecrawled worden, 410 Gone is duidelijk dat de pagina nooit meer terug komt en word bij Google dan ook direct uit de datasets gehaald. Deze pagina’s komen ook niet meer terug in Search Console, zodat het overzicht met 404 errors ook de daadwerkelijk foutief gelinkte pagina’s laat zien en niet vervuild is met URLs van vijf jaar terug.
@Wouter: Google heeft nu meerdere malen aangegeven dat bij interne 301 redirects, bij bijvoorbeeld een migratie van http naar https, het oorspronkelijk Random Surfer model (de kans dat iemand random een link aan klikt is bijvoorbeeld 85%) binnen het PageRank algoritme is weggehaald en er dus geen verlies meer optreed. Bij externe links is dit nog wel het geval. Vandaar dat bij sitemigraties het aanbevolen is je meest waardevolle links aan te laten passen.
Hi Wouter,
Bedankt voor je reactie! Ik begrijp dat je Marketingfacts even aan een scan hebt onderworpen? Helaas is het nu eenmaal zo dat er, vanwege de historie, vaak content is veranderd of een nieuwe locatie heeft gekregen. Die verwijzingen komen vaak van extern. Maar ik zou het intern natuurlijk zo goed mogelijk willen fixen om onnodige 301’s te voorkomen. Heb je grote hoeveelheden ingaande links gezien in je scan? Ik wist overigens niet dat je met een 301 15 procent linkwaarde verliest, goed om te weten, liefst dus ten alle tijden voorkomen…
@Jan-Willem
Dank voor het compliment en dank voor je reactie! Als ik het zo begrijp dan was mijn reactie hierboven te snel en treedt er waarschijnlijk dus geen verlies van linkwaarde meer op.
Een hele waardevolle tip die ‘410 Gone’-header, die heb ik in al m’n zoektochten niet tegengekomen. Maar inderdaad, als er bepaalde content is die niet meer terug gaat komen lijkt me dat een mooie oplossing om ‘m ook daadwerkelijk niet meer terug te hoeven zien. Is toch wat netter dan een 404, omdat het ook echt aangeeft dat hij niet meer terugkomt.
@Jan-Willem,
Interessant dat je dat zegt. Wij hebben bij een paar (wat kleinere) websites de interne 301’s opgelost en we zagen wel verbetering. ( 40 plekken e.d.).
De hoeveelheid 301’s was meestal wel hoger dan een paar procenten van het totale aantal URL’s, soms zelfs opgenomen in het menu.
Hallo Wouter,
Zeker voor kleine websites kan dit al snel impact hebben, niet vanuit het doorgeven van linkwaarde perspectief, maar vanuit het nuttig besteden van crawl budget. Een 301 redirect kost meer laadtijd, 2 benodigde server requests of meer in het geval van de zogenaamde redirect chains en heeft dus vanuit crawl perspectief wel degelijk (negatieve) impact. Weliswaar klein, maar bij kleine websites kan dit flink schelen. Aanpassen van sitewide interne 301 links kan dus best direct een positieve impact hebben op de rankings.
Hi Danny,
Wederom een compliment voor het goede, uitgebreide artikel!
Ik ben erg benieuwd naar jouw mening over de volgende punten:
Hoe gaat Google om met ‘verborgen links’? Ik bedoel hiermee de links die verschijnen bij het uitklappen van een menuoptie (als je met de muis erop gaat staan, dan klapt de optie open met meerdere opties). Geeft Google waarde door aan deze links?
Wat raad je aan t.a.v. de homepage? De homepage krijgt over het algemeen de meeste linkwaarde binnen van andere website. Maar de homepage heeft over het algemeen ook veel links naar andere interne pagina’s. Oftewel al deze links krijgen maar een klein beetje linkwaarde. Raad je aan om het aantal links zoveel mogelijk te beperken? Of bepaalde links bijv. een NOFOLLOW mee te geven?
Hoe gaat Google om met dezelfde links op een pagina? Dus je hebt een pagina en op deze pagina wordt drie keer gelinkt naar dezelfde interne pagina. Gaat dan logischerwijs drie pagina’s van je crawlbudget af, of is Google slim genoeg om dit maar als één ‘crawl’ te rekenen?
Groet,
Sjoerd
Weer wat nieuws geleerd. Over het crawl budget had ik nog nergens anders gelezen.
Bedankt Danny voor dit mooie overzicht. ‘Leuk’ om te zien hoe dit er bij andere bedrijven aan toe gaat en wat de effecten dan zijn. Klinkt bekend… Dus dank je wel!
En zo zie je maar weer dat het bij SEO niet alleen om links verzamelen gaat, maar dat het ook vaak gewoon “werk” is. In ieder geval goed om te zien dat het resultaat oplevert.
Дженерики известных секс стимуляторов по самым низким ценам
Как случился громкий крах Доткомов в начале 90х годов
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!