Zo maak je in 6 stappen de koppeling tussen loyaliteit en NPS-scores
We willen steeds meer weten over websitebezoekers. Zodat we ze vervolgens op kunnen delen in segmenten met als doel dat we klanten en prospects beter kunnen bedienen. Met meer conversies als hoger doel. Klinkt ingewikkeld, maar dat hoeft het niet te zijn; je kunt namelijk heel snel en simpel beginnen.
In dit artikel probeer ik uit te leggen hoe we met een paar simpele stappen al een goed fundament kunnen neerzetten voor verregaande analyses. Als voorbeeld gebruik we in dit artikel een verzonnen elektronicawinkel, die fysieke én online winkels heeft, waarvoor we graag de verhouding tussen loyale klanten en hun net promoter score (NPS) in kaart willen brengen.
Opzet
Om dit allemaal in gang te zetten hebben we een platform nodig. Dit kan variëren van je lokale datawarehouse tot een complex cloudplatform. Tegenwoordig zijn er heel wat betaalbare platformen op de markt. Denk aan Microsoft Azure, Google Cloud Platform, Amazon AWS, et cetera. De meerderheid van deze platformen hebben hun eigen ETL– (een afkorting voor extraction, transformation and load, oftewel het klaarstomen van je data) en analyselaag.
Welke van de dataplatformen het handigst is, hangt af van je doel, de omvang van je datasets en je kennis en vaardigheden. Je kunt trouwens ook besluiten om een platform gedeeltelijk te gebruiken, bijvoorbeeld alleen voor opslag van data.
Stap 0. Strategie uitdenken
- Wat wil ik bereiken?
- Welke analyses moet ik hiervoor doen?
- Welke data heb ik hiervoor nodig?
In dit geval willen we de verhouding tussen loyale klanten en hun NPS in kaart brengen. Hiervoor moeten we eerst bepalen wat de definitie is van een loyale klant. Om het nu simpel te houden gaan we uit van een model waarbij een klant loyaal is, wanneer deze meer dan één keer per jaar een aankoop doet op de website. We hebben dus een overzicht nodig van online aankopen.
We hadden overigens ook de winkelaankopen kunnen meenemen, maar voor de overzichtelijkheid van dit artikel doen we dat niet.
We hebben natuurlijk ook een overzicht nodig van alle NPS- scores die zijn toegekend door de klant. Het belangrijkste is dat alle beschikbare data gekoppeld kunnen worden. Als dit niet mogelijk is kunnen we niet verder. Vandaar ook dat dit stap 0 is: het is een basisvoorwaarde.
In dit voorbeeld slaan we de user-ID van Google Analytics op in onze eigen systemen. Het is dus belangrijk dat deze variabelen gekoppeld worden aan onze lokale gegevensbron (CMS) via het TMS (Tag Management System) of direct in de source van de website. De user-ID van Google Analytics zal dus onze gemeenschappelijke sleutel worden. Hiermee koppelen we de gebruiker tussen Google Analytics en onze systemen.
We moeten dus ook in de NPS-formulieren de user-ID meesturen. Mocht dat niet lukken dan zou je ook een proces kunnen opzetten waarbij je dit matcht op bijvoorbeeld het e-mailadres of een hash hiervan (aangezien je geen e-mailadressen mag opslaan in Google Analytics).
Stap 1. Data-vergaring
- Hoe kom ik aan alle data? (Denk bijvoorbeeld aan een klantenbestand, aan margecijfers en online gedrag)
- Welke afdelingen moet ik hiervoor benaderen?
- Hoe kunnen zij data delen met mij?
Als we de data gekoppeld hebben, kunnen we de eigenaar (bijvoorbeeld de IT-afdeling) vragen ons toegang te geven tot de transactiedata. Deze zetten ze bijvoorbeeld elke dag als CSV-bestand klaar (CSV is vaak het gemakkelijkst en wordt ook breed ondersteund). Zo ook het klantenbestand. De NPS-data halen we op vanuit de servers van een externe partij in een JSON-formaat.
Belangrijk is om altijd een check in te bouwen die je waarschuwt indien de data niet langer goed worden verwerkt. Hoe later je hierachter komt, des te langer je analyse-mogelijkheden stil kunnen komen te liggen. Doe dit in het begin desnoods handmatig (elke dag kijken of de feeds klaarliggen en zijn verwerkt).
Stap 2: Data-transformatie
Op het moment dat we de data hebben, blijkt vaak dat het niet altijd conform onze wensen is ingedeeld. Je kunt bijvoorbeeld data uit Google Analytics niet veranderen van opzet en/of structuur. Dat zul je dus achteraf moeten doen. Er zijn veel tools op de markt die ons kunnen helpen bij het transformeren van de data. Denk bijvoorbeeld aan Excel, R en andere gevestigde namen binnen het ETL-proces.
Er zijn ook tools die zich richten op het transformeren van specifieke data (zoals Google Analytics-data). Voor beginners zijn er ook visuele tools (Analytics Canvas, Talend, Pentaho), waarbij je met drag & drop je transformaties kunt inrichten.
In dit geval moeten we de transactiegegevens koppelen aan het klantenbestand. Dit moeten we namelijk gebruiken om de NPS-data te koppelen aan de transactiefeed.
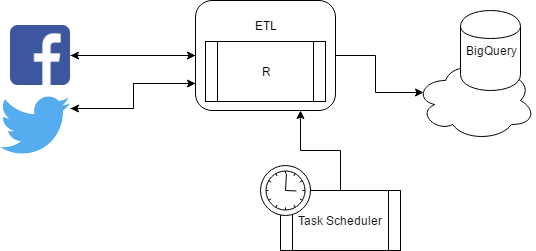
De datasets zijn niet zo complex, dus in dit geval gebruiken we R om de JSON response van de NPS API uit te lezen en te combineren met het transactie- en klantenbestand. We krijgen dus uiteindelijk één CSV-feed met alle transacties, aanvullende klantinformatie en (indien aanwezig) de NPS.
R heeft veel gratis libraries die het werken met verschillende dataformaten en cloudplatformen gemakkelijker maken. In dit geval hebben we de libraries: RCurl (om connectie te maken naar de API van de NPS), jsonlite (om de json reponses van de API plat te maken) en bigrquery (om data door te sturen naar BigQuery) gebruikt. Stap 3 gaat hier verder op in.
![]()
Stap 3: Data-opslag
Nadat we deze stappen hebben gezet, is het noodzakelijk opslag te hebben waarnaar we de data kunnen wegschrijven, om zodoende koppelingen en extracties makkelijker te bewerkstelligen. Het is eventueel mogelijk om Microsoft Access, dan wel Excel (offline) te gebruiken als opslag. Mijn advies is om dit in een cloudomgeving te doen. Denk aan een BigQuery, Google SQL Cloud, Azure of AWS Redshift, etc.
Het voordeel van een cloudomgeving is dat je je minder druk hoeft te maken over de beveiliging van de data. Ook is het verbinden naar je databron makkelijker, omdat er veel libraries zijn die het werk al voor jou doen. Je wilt namelijk een future-proof database (datawarehouse) creëren, die je makkelijk kunt verrijken, waar je makkelijk analyses op kunt uitvoeren en die overal te bereiken is.
Omdat onze elektronicazaak al een BigQuery-omgeving heeft, slaan wij nu alle data daarin op. De samengestelde feed slaan we op als een aparte tabel.
Stap 4: Data-verrijking
Nu we onze database hebben opgebouwd, is het veel makkelijker om nieuwe data toe te voegen.
Dit kan door bijvoorbeeld scripts (R, NodeJS) of applicaties via een Task Scheduler te draaien. Een Task Scheduler is een programma dat meestal op een server draait en vaak ook gratis wordt meegeleverd (in Windows) die het mogelijk maakt om op gezette tijden iets uit te voeren. Denk aan data uit je social media, display en andere kanalen. Het belangrijkste is hier dat we al deze data kunnen koppelen. Voor gebruikers is dit vaak een user-ID, voor producten een product-SKU of product-ID.
Stap 5: Data-extractie
Nu is het belangrijkste dat we uit de opgeslagen data de juiste informatie ophalen. Het is aan te raden om tijdens deze stap nogmaals te kijken naar de aggregatie. Is het nodig om tijdens elke analyse weer gigabytes aan data te doorzoeken of kunnen we ook geaggregeerde statistieken per dag opslaan? Dit kan namelijk veel schelen in de kosten van de cloudomgeving; zwaardere queries die langer duren, kosten ook meer.
Voor de dashboards is het zelfs nog belangrijker om geaggregeerde data te hebben, omdat deze veel sneller werken wanneer statistieken al zijn voorgecalculeerd.
Stap 6: Data-analyse
Er zijn momenteel enorm veel dashboarding en data-analysetools op de markt. Denk aan Google Data Studio, Qlik, Power BI of Tableau. Voor welke tool je kiest, hangt wederom geheel af van jouw specifieke situatie. Soms wordt er al een tool gebruikt binnen de organisatie. Sowieso spelen in de keuze voor een tool, naast de mogelijkheden, ook de kosten en gebruiksvriendelijkheid mee. In dit geval houden we het simpel en verbinden we Excel aan BigQuery, zodat we snel data kunnen ophalen met simpele SQL-achtige opdrachten. Qua architectuur ziet je systeem er dan als volgt uit:
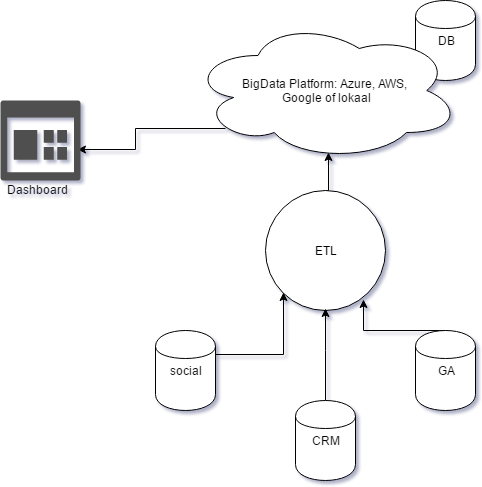
Het komt er nu op neer dat we een query doen waarbij we alle klanten ophalen die meer dan één keer voorkomen in de transactietabel in de afgelopen 365 dagen, want dat zijn onze loyale klanten. Aan de hand van deze klanten kunnen we vervolgens in kaart brengen wat de NPS doet met de frequentie van aankopen.
Conclusie
Ik heb in dit artikel met hele simpele voorbeelden geprobeerd duidelijk te maken dat het echt niet zo lastig hoeft te zijn om diepere analyses te doen op data die je al hebt of makkelijk kunt vergaren.
Uiteraard kun je je data en je analyses veel groter of ingewikkelder maken, maar de kunst is juist om klein te beginnen. Hiermee kun je namelijk veel gemakkelijker het gewenste fingerspitzengefühl ontwikkelen, zowel bij jezelf als in je organisatie. Uiteindelijk is het verstandig om bij complexere trajecten specialisten als database-engineers en econometristen te betrekken. Zij zijn natuurlijk getraind in de juiste methodes en technieken, maar door eerst je basiskennis te ontwikkelen leer je waar de mogelijkheden liggen, wat er nodig is om deze kansen te benutten en zo kun je betrokken specialisten beter aansturen terwijl zij zich buigen over ingewikkelde datakoppelingen en formules.
Tuncay is SEM software engineer en werkt al meer dan 10 jaar voor diverse opdrachtgevers van Traffic Builders. Is altijd in voor een goed gesprek en een grap, wint elke discussie en deelt graag zijn WA/MI en SEM software kennis met collega’s.