Aaaan de slag! (Help, ik heb geen data scientist – deel 4)
Doe-het-zelven aan de hand van de zes stappen van het Cross-Industry Standard Process for Data Mining

Dat je iets met klantdata moet, staat buiten kijf. Maar in de vakmedia lees je iedere week weer over een ander tekort: data scientists, data engineer, ML engineers, analytics translators. Heb je de ambitie om je klant écht beter te begrijpen maar niet de resources die daarbij horen, dan sta je voor een uitdaging. Wat dan? In deze reeks gaan we dieper in op mindset, tools, best practices en technieken die je ook zonder een heel datateam kunt toepassen. Deze laatste editie: werkwijze en tooling.
Eerder in deze serie op Marketingfacts hebben mindset, valkuilen en omstandigheden behandeld. Tijd om de mouwen op te stropen. Als kapstok gebruik ik daarvoor graag Cross-Industry Standard Process for Data Mining (CRISP-DM), een model dat verreweg het meest gebruikt wordt over de hele wereld.
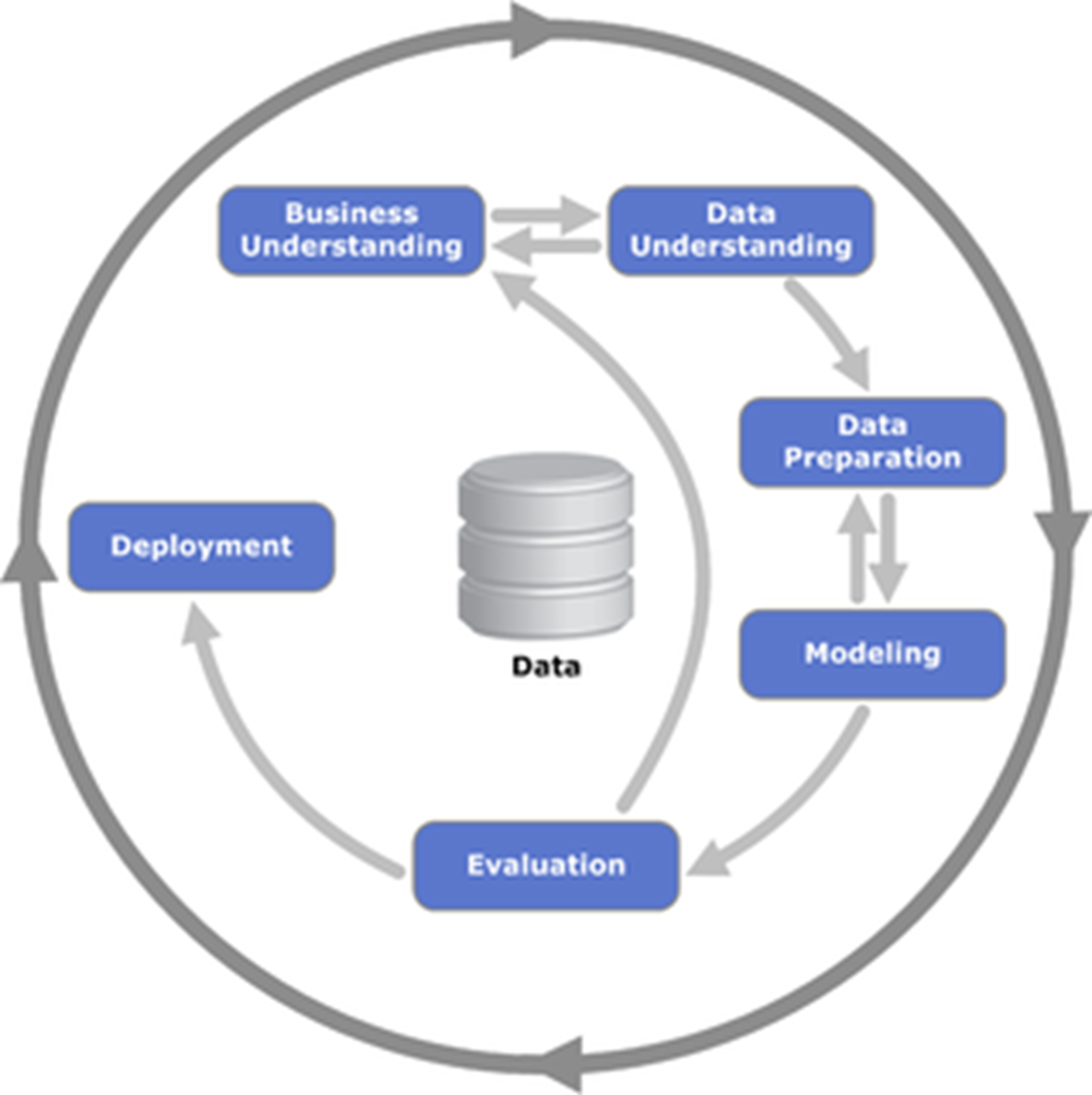
De cyclus heeft wat weg van de wetenschappelijke methode, maar dan met een betere business embedding: wel zo fijn in de praktijk. Het stelt je in staat een project of vraagstuk aan te pakken met een kop en een staart, passend bij de business. Hopelijk voorkom je zo dus dichtgetimmerde analyses waar niemand in de praktijk iets mee kan of oneindige verbeterslagen.
Aan de hand van de zes stappen, geef ik handvaten hiervoor.
Business Understanding: stel duidelijke kaders
Een analysevraag komt niet uit de lucht vallen, maar vloeit voort vanuit een achterliggend doel. Churn verlagen, ROAS verhogen, CLV in kaart brengen: allemaal onderwerpen voor een analist om zich in vast te bijten. Maar zonder het juiste kader vooraf, kan dat zomaar voer worden voor een bureaula. Zorg voor de analyse dat je degene die dit gaat uitvoeren betrekt in je uiteindelijke plan. Het beste antwoord op de vraag die je stelt, kan praktisch totaal onbruikbaar zijn. Stel dus niet de vraag ‘wat maakt dat iemand zijn abonnement opzegt?’, maar ‘kun je van deze 10 knoppen waaraan ik kan draaien, zien of ze effect hebben op de churn?’. Bij die eerste loop je het risico dat je antwoorden krijgt die buiten jouw controle liggen, bij die laatste kan het hooguit zijn dat het antwoord ‘nee’ is. En dan is het weer aan jou als marketeer om je propositie tegen het licht te houden, denk ik.
Data Understanding: plan of botsauto
Vanuit een goede businessvraag, komen vanzelf duidelijke databenodigdheden. Dat is één deel van deze fase: hoe kom ik aan de juiste gegevens. Maar vergeet ook de dataverkenning niet. Je kunt in de volgende fase best wat gaan repareren, maar zorg ervoor dat je nu al in kaart brengt hoe de data eruitziet. Mis je dingen? Hoe is de data verdeeld (hoe groot is het percentage opzeggers)? Gebruik niet alleen tabellen hiervoor, maar ook histogrammen en andere visuals.
Het is heel verleidelijk om gelijk naar het modelleren te springen – toch de krenten uit de pap voor iedere nerd – maar de uiteindelijke tijdswinst zit hem in deze fase. Zonder goed zicht op je data, ga je ontelbare keren op en neer moeten tussen modelleren en problemen fixen (of nog erger, je levert met veel zelfvertrouwen een onbruikbaar model op). Deze fase maakt of de rest van je project verloopt volgens een gedegen plan of meer type botsauto wordt. Ook dan kom je er wel, maar niet zonder je neus te stoten.
Als je niet echt wilt programmeren (en Jupyter notebooks dus geen optie zijn), is een BI-tool als Tableau of MicroStrategy een goede hiervoor. Tellius is een opkomer die vrij gedetailleerde inzichten geeft, maar wel wat overkill is voor alleen deze fase.
Voor een meer alles-in-1-aanpak, kun je tools als Dataiku, RapidMiner en Orange bekijken. Die hebben zowel visualisatie mogelijkheden, als genoeg keuzes om dataprep en modelleren toe te passen.
Data preparation
Die twee lijntjes met Modelling staan er niet voor niks: ongetwijfeld loop je nog tegen uitdagingen aan. Maar na een goede Data Understanding-fase, kan dit wel gestructureerd verlopen. Houd die structuur ook vast: beschrijf wat je gedaan hebt en in welke volgorde. Niks zo erg om in een volgende iteratie – of bij een simpele checkvraag – geen idee meer te hebben wat je hier deed, waarmee je hele project eigenlijk niet duurzaam wordt.
Deze fase omvat concreet zaken als het opvullen van missende waarden, het structureren van tekstwaarden, statische bewerkingen zoals standaardisatie, en het aan elkaar koppelen van verschillende bronnen. Het is geen overdrijving als ik stel dat hiermee de goede en slechte data scientists zich normaal onderscheiden. Iedereen kan de 7 regels Python leren die nodig zijn om een model te trainen, maar wat je in dat model stopt – en hoe – vergt echt wel inzicht in data en dit vakgebied.
Dit kan ook in de tools die ik hierboven noemde, maar dat vraagt wel wat kennis vooraf. Het boek ‘Data Science for Business’ dat ik eerder aanhaalde heeft het hier ook over. Een artikel als dit geeft je nog wat andere concepten om over na te denken.
Tools als Dataiku laten je dit vrij gemakkelijk uitvoeren, maar: het is wel belangrijk te weten wat je doet. Hier kun je voorbeeldprojecten van die tool bekijken, zoals een market basket analysis.
Modelling
Modelleren neigt al gauw naar machine learning en/of statistische modellen. Maar: ook een goede analyse, met rapport of dashboard, kan natuurlijk prima je probleem oplossen. Trap dus niet in de valkuil dat je per se altijd naar artificial intelligence moet reiken om slimme dingen met je data te doen. Bovengenoemde tools helpen je met zowel statische als machine learning modellen. Dit artikel zet een hoop algoritmen op een rijtje, en hier vind je een flowchart voor statische toetsen.
Goed, nu een stap terug. Een model is een versimpelde weergave van de werkelijkheid, zodat je een beslissing kunt maken voor de toekomst. Dat betekent: patronen leren uit historische data. Dan moet die data dus goed zijn én een goede steekproef, anders is je model niet houdbaar. Maar ook de modelkeuze zelf is van belang en dat gaat verder dan ‘welke voorspelt het best’. Uiteindelijk moet een model – in de fase deployment – in gebruik genomen worden. Als het puur gaat om de beste voorspelling – omdat je bijvoorbeeld een score wilt doorgeven aan een decision engine – is een black box prima (ethische discussies even daargelaten, dan). Maar ben je op zoek naar een manier om je callcenter-medewerkers te laten kiezen tussen welke vorm van up-sell werkt voor een klant? Dan is een beslisboom uiteindelijk een stuk makkelijker te lezen dan allerlei moeilijke deep learning modellen.
Evaluation
Wellicht een flashback uit je statistiekonderwijs: de p-waarde. In de toetsende statistiek een belangrijke meetwaarde om de bruikbaarheid van een model te evalueren. Maar: zoveel modellen, zoveel metrics. Dit artikel zet er een aantal uiteen en dat gaat verder dan nerdy stoerdoenerij. Maar naast de selectie van de juiste meetwaarde, is het ook van belang na te denken over een soort benchmark. Voorbeeld: als ik zou roepen dat een model 90% accuraat is, klinkt dat toch best aardig. 90% van de gevallen goed voorspelt, die man mag vroeg naar huis vandaag. Zet dit nu in een context van churn, waarin 5% van je customer base weggaat. Als je dan gewoon onnadenkend iedereen als niet-churn zou bestempelen – niks model – zou je al een accuraatheid van 95% behalen: tenslotte voorspel je dan alleen die 5% churners fout. Dan betekent die 90% van mij toch opeens wél overwerken.
Een andere keuze die van belang is, is of je het bouwen (“trainen”) van je model niet doet op dezelfde data als waarop je die evalueert. Net zo goed als dat een schoolexamen niet dezelfde vragen bevat als de oefeningen vooraf, moet je ook je model toetsen in ongeziene omstandigheden. Dit artikel beschrijft deze zogenaamde train-test-split, met wat voorbeelden in Python.
Deployment
Na al deze hordes, heb je een performant model: gefeliciteerd! Maar zei een ervaren data scientist me ooit: ‘het beste model, is het model dat in gebruik is’. Daar gaat deze fase over. Als het goed is, weet je al vanuit je Business Understanding wat de toepassing van je model gaat zijn. Wil je iedere week een classificatie van je leads? Realtime recommendations in je winkelmandje? Voor het hoogseizoen even de churners aanmerken? Of ging het gewoon om inzicht in wat CLV bepaald? In veel gevallen vergt dit toch een vorm van infrastructuur en een model ‘live’ zetten. Platformen als Openscoring voorzien hier in en cloud vendors als AWS bieden hier ook functionaliteiten voor aan.
Is dit makkelijk als leek? Nee. Het wordt steeds makkelijker, maar dit doe je niet even ‘erbij’. Zorg dus dat je vooraf al goed in kaart brengt wat je nou eigenlijk wilt doen met dat model en of dat wel bij je business past. Ook omdat je werk niet gedaan is als het model in productie is genomen -wat dat voor jou dan ook betekent. Je moet in de gaten houden of het model wel blijft performen, niet nu maar ook over een maand of een halfjaar. Je wilt niet na een jaar erachter komen dat je allang niet meer de juiste leads herkent met je model, omdat de onderliggende data flink is verandert.
Conclusie
Is dit artikel een flinke sprong ten opzichte van die vorige? Wellicht – al boden die vorige artikelen wel een nodige basis. Bedenk ook: niet iedere stap in data science betekent real time voorspellingen doen met state-of-the-art modellen. Het kan ook zijn dat je een verkennende analyse doet op je e-mail performance. Dat kan prima met deze tools en dezelfde werkwijze. Start simpel, doorloop de cyclus, leer ervan, en ga dan eens stapje dieper. Je loopt vanzelf tegen een punt aan dat je ofwel zelf data scientist moet gaan worden, ofwel er eentje moet inhuren. Niet erg, want deze reeks heeft je dan wel voorbereid om daar de goede omstandigheden voor te creëren én een goede sparringpartner te zijn.
Succes!
