Big data-analyse: tweets voorspellen stijging in werkloosheid

Big data is een hot topic. Waar sommige partijen nog moeite hebben met de analyse van hun websitebezoek, schrapen andere partijen data uit vele bronnen bij elkaar voor diepgaande analyse. Tot die laatste categorie behoort ook de Verenigde Naties – meer specifiek Global Pulse, een innovatieplatform van de VN. Uit onderzoek dat SAS namens hen uitvoerde blijkt dat een stijging in de werkloosheid voorspeld kan worden aan de hand van het sentiment en de inhoud van tweets van consumenten.
Het onderzoek van SAS en UN Global Pulse behelsde een analyse van social media-data uit de VS en Ierland van een periode van twee jaar. De data waren afkomstig van een half miljoen blogs, fora en nieuwssites en werd beoordeeld op verwijzingen naar werkloosheid en de manier waarop mensen hiermee omgaan.
Sentiment en kwantiteit
Het sentiment en de hoeveelheid berichten werden vergeleken met de officiële werkloosheidsstatistieken om te zien of stijgingen van bepaalde onderwerpen indicatief waren voor pieken in de werkloosheid. De uitkomst was, dat verandering in het sentiment en de inhoud binnen conversaties op social media zouden kunnen waarschuwen voor een mogelijke stijging in werkloosheid.
Zo bleek dat er een grotere kans was op een stijging in werkloosheid naarmate er meer gepraat werd over bezuinigen op de boodschappen, een toenemend gebruik van het openbaar vervoer en een kleinere auto – zogenaamde leading indicators. Ook waren er specifieke onderwerpen die vooral aan de orde kwamen ná een piek in de werkloosheid, zoals geannuleerde vakanties, verminderde uitgaven voor gezondheidszorg, en gedwongen huizenverkoop (foreclosures) of ontruimingen – lagging indicators.
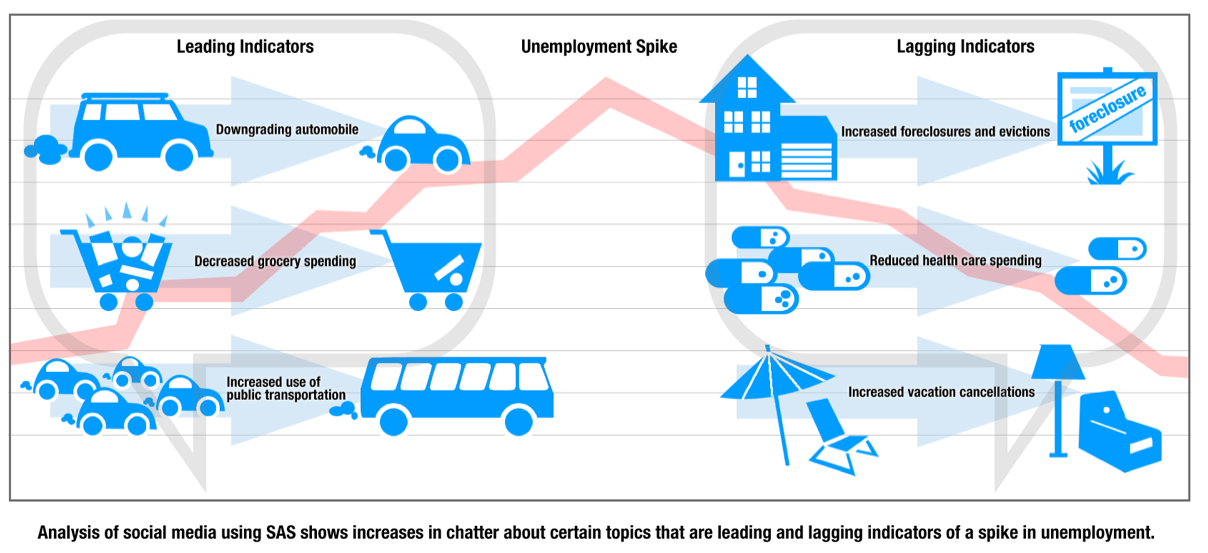
Bij het analyseren van het sentiment van berichten kreeg elke verwijzing naar werkloosheid een “mood score” op basis van toon: zijn werklozen optimistisch over de toekomst of juist d Depressief over de vooruitzichten? De gegevens werden vervolgens gesorteerd op thema's als huisvesting, vervoer en financiën, aan de hand van termen als “auto teruggenomen” of “foreclosure.”
In de VS trad een duidelijke stijging op van een”vijandige” of “depressieve” stemming, vier maanden vóór de piek in werkloosheid. In Ierland waren het meer verhogingen van een “angstig” type gesprek die konden worden gecorreleerd met een werkloosheidpiek vijf maanden later. Een verhoogde hoeveelheid “verwarde” gesprekken ging drie maanden vooraf aan de piek, terwijl gesprekken met “vertrouwen” nog twee maanden daarna aanzienlijk minder plaatsvonden.
Dashboard
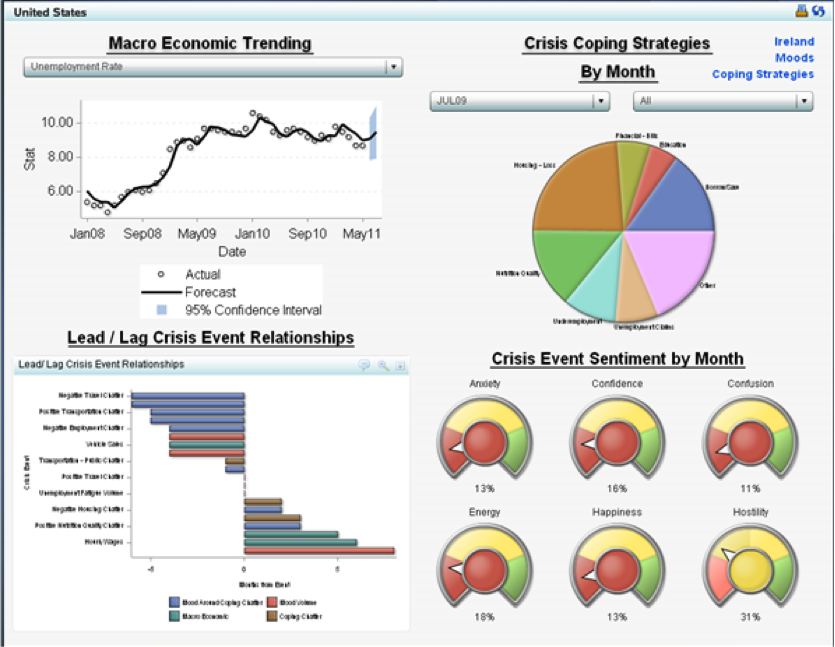
UN Global Pulse ziet grote mogelijkheden voor dergelijke analyse en onderzoekt hoe nieuwe soorten gegevens de officiële statistieken kunnen versterken of aanvullen als het gaat om de manier waarop mondiale crises gevolgen hebben voor mensen. De realtime feedback die wordt verkregen kan worden vervat in een dashboard dat voor beleidsmakers de mogelijkheid biedt om ontwrichtende gebeurtenissen beter te beheren. Of zoals VN-secretaris-generaal Ban Ki-moon het omschreef: “We moeten het gebruiken om ons te vertellen wat er gebeurt, terwijl het gebeurt.”
De research paper van UN Global Pulse is hieronder te lezen.
Meer informatie over Big Data krijg je ook tijdens Online Tuesday #26 op dinsdag 12 juni a.s.!
Ik werk als consultant bij Evolve, een bureau dat is gespecialiseerd in het verbeteren van de interne communicatie en interne processen met behulp van interne sociale media. Was voorheen hoofdredacteur bij Marketingfacts en betrokken bij o.a. Online Tuesday en NIMA.
Het vak Statistiek, wat ik zelf een ‘moetje’ vond, krijgt duidelijk een steeds grotere rol in de online marketing wereld. Mooi dat je in het artikel ook aangeeft dat behalve de correlaties, ook voorspellingen op basis van deze data gedaan kan worden.
Met het steeds groter groeiende openbare berichten (Twitter natuurlijk) en de steeds beter wordende tools en API-koppelingen, wordt Big Data steeds relevanter. Ik vind wel dat we kritisch moeten blijven, aangezien conclusies (zelfs met véél data) soms te makkelijk getrokken worden.
Ik ben het met Bart eens. Uitkijken voor een self fulfilling prophecy lijkt me. Wel cool om na te denken over de mogelijkheden van “Big data”. In relatie tot de beurs maar ook binnen gezondheidszorg (uitbraken en herkomst van een epidemie bijvoorbeeld) veel kansen.
@Bart, @Siem: ook eens. Hoe meer data, hoe groter de kans dat er een correlatie optreedt. En dan is het erg aantrekkelijk om daar ook een causaal verband in te zien.
Ik ben benieuwd of hier niet hetzelfde effect optreedt als in ‘normale’ analytics: the more you know, the better you know how little you know. Oftewel: zodra je wilt gaan meten, loop je al gauw tegen de grenzen van je data aan. Want waar komt dat effect vandaan?
Overigens is het grote voordeel van big data wel, dat je steeds makkelijker o.b.v. historische gegevens je hypothese kunt testen en niet eerst een jaar aan dataverzameling hoeft te doen. Afijn, benieuwd hoe dit uitpakt!
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!